Trong thế giới phức tạp của website và công nghệ web, file robots.txt đóng vai trò quan trọng như một bảo vệ vững chắc, đảm bảo sự điều khiển đúng đắn đối với việc truy cập thông tin trên trang web. Điều này không chỉ liên quan đến sự bảo mật mà còn ảnh hưởng trực tiếp đến việc tối ưu hóa công cụ tìm kiếm. Để hiểu rõ hơn về tác động và ưu điểm của file robots.txt, chúng ta cần tìm hiểu về nó từ những khái niệm cơ bản. Hãy cùng IT Vũng Tàu khám phá kiến thức cơ bản về file robots.txt là gì? để xây dựng và duy trì một hệ thống website hoạt động mạnh mẽ và an toàn.

File Robots.txt là gì?
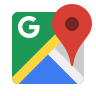
File robots.txt là một tệp văn bản đơn giản được đặt trên máy chủ web để điều khiển hoặc hạn chế quyền truy cập của các robots và web crawlers đến các phần cụ thể của trang web. Điều này giúp quản trị viên trang web kiểm soát cách thông tin trên trang được index và xuất hiện trên các công cụ tìm kiếm. Robots.txt hoạt động như một “hướng dẫn” cho các robots của công cụ tìm kiếm, chỉ rõ rằng trang web muốn hoặc không muốn được quét trong các khu vực nhất định.
File này thường được đặt ở gốc trang web và có thể chứa các chỉ thị như “User-agent” để xác định robot cụ thể, và “Disallow” để chỉ định các phần cụ thể mà robot không được phép truy cập. Mặc dù robots.txt có thể giúp kiểm soát quyền truy cập, nhưng nó không phải là một biện pháp bảo mật chặt chẽ và nên được sử dụng cùng với các biện pháp bảo mật khác để đảm bảo an toàn trực tuyến.
Thuật ngữ phổ biến của File Robots.txt
Khi làm quen với file robots.txt, có một số thuật ngữ phổ biến mà bạn có thể gặp khi nghiên cứu và cấu hình file này. Dưới đây là một số thuật ngữ quan trọng:
- User-agent: Đây là tên của robot hoặc web crawler mà bạn muốn áp dụng các quy tắc cho. Nếu bạn muốn áp dụng quy tắc cho tất cả các robot, bạn có thể sử dụng “User-agent: *”.
- Disallow: Đây là một chỉ thị trong file robots.txt để nói với robot không được phép truy cập vào các phần cụ thể của trang web. Ví dụ: “Disallow: /private/” sẽ ngăn chặn robot truy cập vào thư mục “private” trên trang web.
- Allow: Ngược lại với Disallow, Allow cho phép robot truy cập vào các phần cụ thể của trang web. Nếu có một chỉ thị Allow và một chỉ thị Disallow cho cùng một URL, thì Allow có ưu tiên.
- Crawl-delay: Chỉ định một khoảng thời gian trễ giữa các yêu cầu của robot, giúp giảm áp lực lên máy chủ và bảo vệ trang web khỏi việc bị quét quá mức.
- Sitemap: Một đường dẫn đến file sitemap.xml, cung cấp thông tin cụ thể về cấu trúc của trang web. Một số robots có thể sử dụng sitemap để hiểu rõ hơn về cách trang web được tổ chức.
- Wildcard: Sử dụng dấu ‘‘ như một ký tự đại diện, cho phép bạn áp dụng quy tắc cho nhiều URL cùng một lúc. Ví dụ: “Disallow: /images/.jpg” sẽ ngăn chặn robot truy cập vào tất cả các file hình ảnh có định dạng .jpg trong thư mục “images”.
Những thuật ngữ này giúp bạn hiểu rõ hơn về cách file robots.txt hoạt động và cách bạn có thể điều chỉnh nó để quản lý việc quét của các robots trên trang web của mình.
Lợi ích khi tạo File Robots.txt
Tạo và quản lý file robots.txt mang lại nhiều lợi ích quan trọng cho quản trị viên trang web và sự hiệu quả của trang web nói chung. Dưới đây là một số lợi ích chính:
- Kiểm soát quyền truy cập: File robots.txt cho phép bạn kiểm soát quyền truy cập của các robots và web crawlers đến trang web của bạn. Bạn có thể chỉ định những phần nào của trang web được quét và index, giúp bảo vệ thông tin quan trọng hoặc những trang không muốn xuất hiện trên các công cụ tìm kiếm.
- Tối ưu hóa SEO: Bằng cách sử dụng file robots.txt, bạn có thể tối ưu hóa quá trình tìm kiếm và cải thiện hiệu suất SEO của trang web. Bạn có thể hướng dẫn robots tập trung vào việc quét các phần quan trọng của trang web, giúp công cụ tìm kiếm hiểu rõ nội dung và cấu trúc của bạn.
- Giảm áp lực lên máy chủ: Bạn có thể sử dụng chỉ thị “Crawl-delay” để giảm tốc độ quét của robots, giảm áp lực lên máy chủ web. Điều này đặc biệt hữu ích đối với trang web có lượng truy cập lớn và tài nguyên máy chủ hạn chế.
- Bảo vệ dữ liệu nhạy cảm: Bạn có thể sử dụng robots.txt để ngăn chặn truy cập vào các phần của trang web chứa thông tin nhạy cảm hoặc không muốn công khai. Điều này đặc biệt quan trọng khi bạn muốn bảo vệ quyền riêng tư hoặc thông tin độc quyền.
- Tăng tốc độ tải trang: Bằng cách ngăn chặn robots quét những phần không quan trọng của trang web, bạn có thể giảm thời gian và tài nguyên cần thiết để quét trang. Điều này có thể dẫn đến tốc độ tải trang nhanh hơn cho người dùng.
Việc tạo và quản lý file robots.txt là một phần quan trọng của chiến lược quản lý trang web, đảm bảo sự hiệu quả và an toàn trong việc quản lý quyền truy cập và tối ưu hóa trải nghiệm người dùng.
File Robots.txt có những hạn chế gì?
Mặc dù file robots.txt mang lại nhiều lợi ích cho quản trị viên trang web, nhưng cũng tồn tại một số hạn chế và hạn chế khi sử dụng nó:
- Không phải là biện pháp bảo mật mạnh mẽ: File robots.txt không phải là một biện pháp bảo mật chặt chẽ. Bất kỳ robot nào có thể chọn không tuân theo các chỉ thị trong file này. Nó không phải là cách để ngăn chặn truy cập không hợp pháp hoặc tấn công mạng.
- Không tất cả các robots đều tuân theo: Mặc dù hầu hết các công cụ tìm kiếm hàng đầu đều tôn trọng file robots.txt, nhưng không phải tất cả các robots đều tuân theo nó. Có một số web crawler không tôn trọng hoặc bỏ qua file này, điều này có thể dẫn đến việc trang web của bạn vẫn bị quét mặc dù bạn đã cấm.
- Không bảo vệ quyền riêng tư hoặc thông tin nhạy cảm: File robots.txt chỉ là một “hướng dẫn” cho robots, nhưng không phải là biện pháp bảo vệ quyền riêng tư hoặc thông tin nhạy cảm. Nếu thông tin quan trọng cần được bảo vệ, các biện pháp bảo mật khác như SSL hoặc phương pháp mã hóa cần được triển khai.
- Không kiểm soát đối với các robots xấu: Các robots xấu có thể bỏ qua file robots.txt và tiếp tục quét trang web của bạn một cách không hạn chế. Điều này đặc biệt quan trọng nếu trang web của bạn chứa nội dung nhạy cảm và bạn cần một lớp bảo vệ mạnh mẽ hơn.
- Có thể gây nhầm lẫn nếu không được cấu hình đúng: Nếu file robots.txt không được cấu hình chính xác, có thể dẫn đến việc trang web của bạn không được index đúng cách hoặc mất khả năng hiển thị trên các công cụ tìm kiếm.
Tóm lại, file robots.txt có những hạn chế và không thể đáp ứng mọi yêu cầu bảo mật. Để đảm bảo an toàn và bảo mật tốt nhất cho trang web của bạn, nên kết hợp sử dụng file robots.txt với các biện pháp bảo mật khác.
Cách hoạt động của File Robots.txt
File robots.txt hoạt động dựa trên một số chỉ thị và quy tắc đơn giản được xác định trong nó. Dưới đây là cách file robots.txt hoạt động:
- User-agent:
- Chỉ thị “User-agent” xác định robot hoặc web crawler cụ thể mà bạn muốn áp dụng các quy tắc cho. Nếu bạn muốn áp dụng quy tắc cho tất cả các robot, bạn sử dụng “User-agent: *”.
- Disallow:
- Chỉ thị “Disallow” chỉ định các phần của trang web mà robot không được phép quét hoặc index. Nếu có nhiều chỉ thị “Disallow”, robot sẽ tuân theo chỉ thị cuối cùng.
- Allow:
- Chỉ thị “Allow” được sử dụng để cho phép robot truy cập vào các phần cụ thể của trang web mà “Disallow” có thể đã cấm. Nếu có nhiều chỉ thị “Allow” cho cùng một URL, chỉ thị cuối cùng được ưu tiên.
- Wildcard:
- Dấu ‘‘ được sử dụng làm ký tự đại diện, cho phép áp dụng quy tắc cho nhiều URL cùng một lúc. Ví dụ: “Disallow: /images/.jpg” sẽ ngăn chặn robot truy cập vào tất cả các file hình ảnh có định dạng .jpg trong thư mục “images”.
- Crawl-delay:
- Chỉ thị “Crawl-delay” xác định khoảng thời gian giữa các yêu cầu của robot. Điều này giúp giảm tốc độ quét, giảm áp lực lên máy chủ, và thậm chí làm giảm độ trễ cho các trang web máy chủ yếu đuối.
- Sitemap:
- Dùng để chỉ định đường dẫn đến file sitemap.xml. Sitemap cung cấp thông tin chi tiết về cấu trúc của trang web.
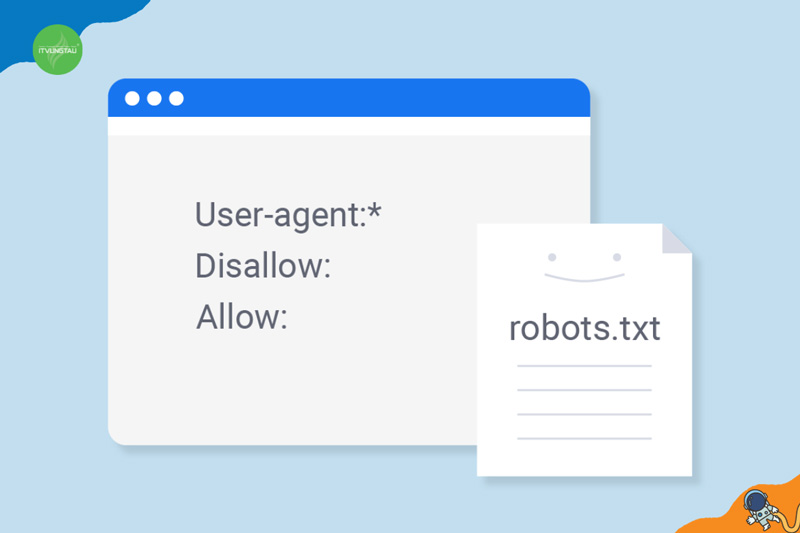
Khi một robot truy cập trang web, nó sẽ kiểm tra file robots.txt để xem liệu nó được phép quét trang web đó hay không. Nếu có chỉ thị “Disallow” tương ứng với phần của trang web, robot sẽ tuân thủ và không quét nó. Ngược lại, nếu có chỉ thị “Allow,” robot sẽ được phép quét các phần đó.
Lưu ý rằng một số robots có thể bỏ qua file robots.txt và quét trang web mà không tuân theo các chỉ thị. Do đó, file robots.txt không phải là một biện pháp an toàn hoàn chỉnh, và nó nên được sử dụng cùng với các biện pháp bảo mật khác.
Hướng dẫn cách kiểm tra File robots.txt cho Website
Kiểm tra file robots.txt của một trang web là một bước quan trọng để đảm bảo rằng các robots và web crawlers hiểu và tuân theo các quy tắc mà bạn đã đặt ra. Dưới đây là một số cách bạn có thể sử dụng để kiểm tra file robots.txt của một trang web:
Cách 1: Truy cập trực tiếp trên trình duyệt:
- Mở trình duyệt web: Sử dụng trình duyệt web (chẳng hạn Chrome, Firefox, hoặc Edge) và truy cập trang web bạn quan tâm.
- Thêm “/robots.txt” vào URL: Gõ “/robots.txt” vào địa chỉ URL của trang web sau domain. Ví dụ: https://www.itvungtau.net/robots.txt.
- Xem file robots.txt: Trình duyệt sẽ hiển thị nội dung của file robots.txt, cho bạn biết các chỉ thị mà trang web đã đặt ra cho robots.
Cách 2: Sử dụng công cụ trực tuyến:
Có một số công cụ trực tuyến giúp bạn kiểm tra file robots.txt một cách thuận tiện. Một số trang web cung cấp dịch vụ này, và bạn có thể sử dụng công cụ như “Google Search Console” để kiểm tra và kiểm soát file robots.txt cho trang web của bạn.
Cách 3: Sử dụng Command Line hoặc Terminal:
Nếu bạn là một người phát triển hoặc quản trị hệ thống, bạn có thể sử dụng Command Line hoặc Terminal để kiểm tra file robots.txt. Sử dụng lệnh như curl hoặc wget để truy cập và hiển thị nội dung của file.
Ví dụ với lệnh curl:
- curl https://itvungtau.vn/robots.txt
Cách 4: Sử dụng Công cụ Kiểm tra Robots.txt của Google:
Google cung cấp một công cụ trực tuyến để kiểm tra file robots.txt của trang web. Bạn có thể truy cập địa chỉ: Google Robots.txt Tester và nhập URL của trang web để kiểm tra.
Lưu ý quan trọng:
- Khi kiểm tra, hãy đảm bảo rằng file robots.txt không chứa các lỗi cú pháp hoặc lỗi nào có thể gây hiểu lầm cho robots.
- Nếu bạn phát hiện vấn đề, bạn có thể cần chỉnh sửa file robots.txt và kiểm tra lại để đảm bảo nó hoạt động như mong đợi.
Bằng cách kiểm tra file robots.txt, bạn có thể đảm bảo rằng các robots có thể hiểu và tuân theo các quy tắc mà bạn đã thiết lập, giúp quản lý quyền truy cập vào trang web của bạn một cách chính xác.
Một số quy tắc cần bổ sung vào File Robots.txt WordPress
Khi bạn sử dụng WordPress, việc cấu hình file robots.txt có thể giúp bạn kiểm soát cách các công cụ tìm kiếm quét trang web của bạn. Dưới đây là một số quy tắc mà bạn có thể bổ sung vào file robots.txt của WordPress để tối ưu hóa quyền truy cập và SEO:
1. Ngăn chặn các thư mục quan trọng:
- User-agent: *
- Disallow: /wp-admin/
- Disallow: /wp-includes/
- Disallow: /wp-content/plugins/
- Disallow: /wp-content/themes/
- Disallow: /wp-content/uploads/
Những chỉ thị trên sẽ ngăn chặn robot truy cập vào các thư mục quan trọng như trang quản trị, thư mục plugin, theme và uploads.
2. Ngăn chặn các URL đặc biệt:
- User-agent: *
- Disallow: /trackback/
- Disallow: /feed/
- Disallow: /comments/
- Disallow: */trackback/
- Disallow: */feed/
- Disallow: */comments/
- Disallow: /page/
- Disallow: /tag/
- Disallow: /category/
- Disallow: /author/
Chặn các URL như trackbacks, feeds, và trang comments giúp giảm lượng thông tin không cần thiết trên công cụ tìm kiếm.
3. Hướng dẫn robots không tìm kiếm các trang phiên bản:
- User-agent: *
- Disallow: /*?*
Chặn các trang có tham số query để tránh việc tạo ra nhiều phiên bản trang không cần thiết trong kết quả tìm kiếm.
4. Cho phép quét các trang tìm kiếm nội dung:
- User-agent: *
- Allow: /search/
- Disallow: /search/*.html
- Disallow: /search/*.php
- Disallow: /search/*.xml
Điều này cho phép quét trang kết quả tìm kiếm của WordPress, nhưng ngăn chặn các phiên bản được tạo ra với các định dạng khác nhau.
5. Hạn chế tần suất quét:
- User-agent: *
- Crawl-delay: 10
Chỉ định một khoảng thời gian trễ giữa các yêu cầu của robot, giảm áp lực lên máy chủ.
Lưu ý quan trọng:
- Kiểm tra thường xuyên: Luôn kiểm tra file robots.txt sau khi thêm hoặc sửa đổi để đảm bảo rằng nó không gặp vấn đề cú pháp hoặc lỗi khác.
- Chú ý đến các plugin SEO: Nếu bạn đang sử dụng plugin SEO như Yoast SEO hoặc All in One SEO Pack, chúng thường có tính năng để tạo và quản lý file robots.txt, và bạn có thể cần kiểm tra cấu hình của chúng trước khi thêm quy tắc thủ công.
Nhớ rằng mọi trang web có yêu cầu và yêu cầu cụ thể của mình, nên điều chỉnh file robots.txt dựa trên nhu cầu cụ thể của bạn là quan trọng.

Những lưu ý khi dùng File Robots.txt
Khi sử dụng file robots.txt, có một số lưu ý quan trọng bạn cần xem xét để đảm bảo rằng nó đang hoạt động đúng cách và không gây ra vấn đề cho trang web của bạn:
1. Kiểm tra Thường Xuyên:
- Luôn kiểm tra file robots.txt của bạn sau khi thêm, sửa đổi, hoặc cập nhật nó để đảm bảo rằng không có lỗi cú pháp và các chỉ thị đang được hiểu đúng.
2. Kiểm tra Hiệu Suất:
- Một số chỉ thị trong file robots.txt, như “Crawl-delay,” có thể ảnh hưởng đến hiệu suất của trang web. Kiểm tra xem việc áp dụng các chỉ thị như vậy có tác động tích cực hay không.
3. Chú Ý Đến Sự Tuân Thủ:
- Một số web crawlers có thể không tuân theo file robots.txt. Chú ý đến những robot không tuân thủ và xem xét biện pháp bảo mật khác nếu cần.
4. Đảm Bảo Không Gặp Xung Đột với Plugin SEO:
- Nếu bạn sử dụng các plugin SEO như Yoast SEO hoặc All in One SEO Pack, hãy kiểm tra xem chúng có tạo và quản lý file robots.txt không. Tránh xung đột thông tin và chỉ thị giữa các nguồn khác nhau.
5. Chú Ý Đến Quy Tắc “Allow” và “Disallow”:
- Chắc chắn rằng quy tắc “Allow” và “Disallow” không xung đột với nhau. Nếu có, robot sẽ tuân theo quy tắc cuối cùng được chỉ định.
6. Ngăn Chặn Quyền Riêng Tư và Thông Tin Nhạy Cảm:
- File robots.txt không phải là biện pháp bảo mật chặt chẽ, nên tránh sử dụng nó để ẩn thông tin nhạy cảm hoặc quyền riêng tư quan trọng.
7. Chú Ý Đến Sitemap:
- Nếu bạn chỉ định sitemap trong file robots.txt, đảm bảo rằng sitemap đó là chính xác và không chứa lỗi.
8. Chú Ý Đến Thay Đổi Trang Web:
- Khi bạn thực hiện thay đổi lớn trên trang web, như việc thay đổi cấu trúc URL hoặc di chuyển nội dung, hãy xem xét và cập nhật file robots.txt nếu cần thiết.
9. Kiểm Soát Cẩn Thận với Wildcards:
- Sử dụng dấu ‘*’ cẩn thận. Đôi khi, sử dụng wildcards có thể dẫn đến việc ngăn chặn quét những phần của trang web mà bạn không mong muốn.
10. Bảo Mật Tốt Hơn với HTTPS:
- Nếu trang web của bạn sử dụng HTTPS, hãy đảm bảo rằng file robots.txt cũng được phục vụ qua HTTPS để bảo vệ tính toàn vẹn và bảo mật.
Nhớ rằng mọi trang web là duy nhất, và việc cấu hình file robots.txt phải phản ánh đúng nhu cầu cụ thể của trang web và chiến lược SEO của bạn.
Câu hỏi thường gặp về File Robots.txt
Dưới đây là một số câu hỏi thường gặp về file robots.txt:
1. Robots.txt là gì và tại sao cần sử dụng nó?
- Robots.txt là một tệp văn bản đặt trên máy chủ web để hướng dẫn các robots và web crawlers về cách nên quét và index nội dung trên trang web. Sử dụng nó giúp kiểm soát quyền truy cập, tối ưu hóa SEO, và giảm áp lực lên máy chủ.
2. Làm thế nào để tạo một file robots.txt?
- Bạn có thể tạo một file robots.txt bằng cách sử dụng bất kỳ trình soạn thảo văn bản nào và lưu lại với tên là “robots.txt”. Đặt tệp này tại gốc trang web của bạn.
3. Làm thế nào để kiểm tra xem file robots.txt của trang web đang hoạt động đúng cách không?
- Bạn có thể kiểm tra bằng cách thêm “/robots.txt” vào URL của trang web, hoặc sử dụng các công cụ trực tuyến hoặc lệnh trên Command Line.
4. Làm thế nào để thêm quy tắc Allow cho một thư mục cụ thể?
- Sử dụng chỉ thị “Allow” trong file robots.txt và chỉ định đường dẫn của thư mục đó. Ví dụ:
Allow: /images/.
5. Quy tắc “Disallow” và “Allow” có ưu tiên như thế nào?
- Nếu có quy tắc “Allow” và “Disallow” cho cùng một URL, “Allow” có ưu tiên. Tuy nhiên, nếu có nhiều quy tắc “Allow” hoặc “Disallow” cho cùng một URL, quy tắc cuối cùng được áp dụng.
6. Làm thế nào để ngăn chặn một robot cụ thể?
- Sử dụng chỉ thị “User-agent” để xác định robot cụ thể và sau đó sử dụng “Disallow” để ngăn chặn quét các phần của trang web.
7. Robots.txt có thể bảo mật trang web không?
- Không, robots.txt không phải là biện pháp bảo mật mạnh mẽ. Nó chỉ là một “hướng dẫn” cho robots và nên được sử dụng cùng với các biện pháp bảo mật khác như SSL để bảo vệ trang web.
8. Làm thế nào để giảm tần suất quét của các robots?
- Sử dụng chỉ thị “Crawl-delay” để chỉ định khoảng thời gian trễ giữa các yêu cầu của robot. Ví dụ:
Crawl-delay: 10để đặt thời gian trễ là 10 giây.
9. Làm thế nào để chỉ định sitemap trong robots.txt?
- Sử dụng chỉ thị “Sitemap” để chỉ định đường dẫn đến file sitemap.xml. Ví dụ:
Sitemap: https://www.example.com/sitemap.xml.
10. Làm thế nào để kiểm soát quyền truy cập của các web crawler trên các trang tìm kiếm?
- Sử dụng quy tắc “Disallow” để ngăn chặn quét các phần không mong muốn và “Allow” để cho phép quét các phần cụ thể. Điều này giúp kiểm soát quyền truy cập của các web crawler và cải thiện SEO.
Kết luận
File robots.txt là một công cụ quan trọng giúp quản lý quyền truy cập của các robots và web crawlers đến trang web của bạn. Việc cấu hình đúng file này không chỉ giúp tối ưu hóa SEO mà còn đảm bảo an toàn thông tin, giảm áp lực lên máy chủ, và kiểm soát hiệu suất của trang web. Bằng cách sử dụng các chỉ thị như Disallow, Allow, Crawl-delay, và Sitemap, bạn có thể điều chỉnh cách các công cụ tìm kiếm hiểu và xử lý trang web của mình.
Tuy nhiên, lưu ý rằng file robots.txt không phải là biện pháp bảo mật hoàn chỉnh và không thể ngăn chặn tất cả các truy cập không mong muốn. Để đạt được bảo mật tốt nhất, nó nên được kết hợp với các biện pháp bảo mật khác như SSL và kiểm soát truy cập người dùng.
Cuối cùng, quản lý file robots.txt là một phần quan trọng của chiến lược quản lý trang web, đặc biệt là trong bối cảnh ngày càng phức tạp của thế giới kỹ thuật số. Điều này không chỉ giúp tối ưu hóa trang web của bạn mà còn đảm bảo rằng thông tin của bạn được quản lý và bảo vệ một cách hiệu quả.